11.1 導入
ソフトウェア設計の数量的解析(quantitive analysis of a softweare design): 与えられたハードウェア構成の元、与えられている負荷で概念的にソフトウェアを実行してみること。
効用: 効率上の潜在的な問題の早期発見、別のソフトウェア設計や別のハードウェア構成の調査。
この章では
l 効率のモデル化(performance modeling)
とそれに対する
l 実時間スケジューリング理論(real-time scheduling theory)
の適用を通じてソフトウェア設計の効率解析に対する概観を提供する。
実時間スケジューリング理論は、厳しい時間制約を持つハードな実時間システム(hard real-time system)に特に適する。
11.2 効率モデル
11.2.1概念
効率モデル(performance model): システムの効率の観点から実際の計算機システムを抽象化したもの。システムが実在するか否かは問わない。
形式
数学的なモデル(mathematical model):システムの数学的表現(例:待ち行列モデル、Petriネット・モデル、回帰モデル)
シミュレーション・モデル(simulation model):システムの構造と挙動のアルゴリズム的表現)。
種類
静的モデル(static model):時間経過を全く加味しない、あるいは定常状態に関するモデル(例:回帰モデル、定常状態を扱う多くの待ち行列モデル)
動的モデル(dynamic model):時間経過を考えるモデル(例:シミュレーション・モデル)
回帰モデルについて
幾つかのモデル(たとえば回帰モデル(regression model)のような経験的なモデル)は、計測して多くのデータが集めることができる既存のシステムの分析に向く。⇒ 標本に対する統計的な曲線の当てはめ(例: 効率に関するデータに対する最小二乗法等)に基づく回帰モデルは既存のシステムの分析に有用。⇒ しかし、まだ存在していない、これからモデル化しようとしている対象には回帰モデルは向かない。
11.2.2 待ち行列モデル
待ち行列モデル(queueing model): 限りある資源の取り合いの様子を解析してシステムの効率を予測するモデル。
l 解析的なモデルでは問題の数学的表現から解が直接推論できる。
l 通常は、解析しやすいように仮定が置かれる。
仮定の例: 「記憶なし」(”memory-less”)属性=最後の要求からの経過時間とは独立に新たな要求が発生する。⇒要求の時間間隔の分布は指数分布(最高の確率密度を最小の時間間隔である0とする・・・多くの計算環境における最小の時間間隔はそうなっていないが・・・。)になる。(定常状態の解析に限ればさらに簡単化のための仮定が置かれる。)
l 待ち行列モデルは、計算機システムの概観を提供し、システムが要求を達成できるかどうかについての高レベルなモデルとして有用。⇒より詳細な効率の解析には他のモデル化技法が必要。
11.2.3 シミュレーション・モデル
シミュレーション・モデル(simulation model):実世界におけるシステムの構造と挙動をアルゴリズムとして抽象化したもの。
l 設計が健全で時間的要求を達成できるかどうかを検証する効果的な方法。
l 開発中、さらには開発前のシステムを稼動中と同様にシミュレートできる。
l モデル内に作りこむ仮定が現実的なものになるように注意。
l 動的なモデル(時間経過を明示的に取り扱う。)である。
l 一定期間に渡ってシステムの挙動を解析できる。
離散イベント・シミュレーション・モデル(discrete event simulation model): システムの全ての状態変化をそれぞれ離散的なイベントとして表現。⇒イベント間の時間を飛ばしてシミュレーションの所要時間を「圧縮」できる。
計算機システム・シミュレーション・モデル(computer system simulation model): 実際の計算機の挙動やハードウェア上での設計ソフトウェアの実行をモデル化。入力=抽象化された負荷(workload)、出力=計算機の挙動を示す評価結果。
負荷について
よくある方法: 負荷を確率分布(probability distribution、しばしば負荷に関して正当化されてはいない仮定を置く)でモデル化する。
別の方法: 負荷をイベント系列(event trace、イベントは種類と時刻の組で表され、到着時間順に並べられる)でモデル化する。(既存のシステムについては、イベント系列は実際に計算機を監視して得る。存在していないシステムについては稼動させる実世界を観測して得る。)
11.2.4 計算機システムをモデル化する際の問題
費用対効果
数多くの要素を考慮に入れる必要。例:モデル開発の費用、詳細さの度合い、完成したモデルの早さ、精度。
一般にモデルの忠実さと費用にはトレード・オフがある。(シミュレーションは最も詳細に高精度にできる一方モデル化に掛かる費用が高いので適切な詳細度を選ぶ必要がある。)
1つの解決策: 混合モデル(hybrid model)の利用。1つ以上のモデル化技法を組み合わせる。例:待ち行列/シミュレーション・モデル、シミュレーション/回帰モデル。
システム中で特に詳細に知りたい部分⇒シミュレーション・モデル技法
その他の相対的にあまり興味がない部分⇒待ち行列モデル技法や回帰モデル技法
検定と較正
実世界との整合性を較正(calibration)し検証(validation)する必要。
l 既存のシステムの場合、実システムの効率を計測して得られたデータが利用できる。
l 通常、較正と検定の過程はモデルの予測が実世界での効率と大きく違わないようにする統計的な反復の過程。
l 一旦較正と検定が終わればシミュレーション上で「もし〜だったら(”what if”)」シナリオの検討ができる。
l まだ実在しないシステムの効率モデルについて較正と検証の過程は、より間違いを含み勝ち(error-prone)。
l OSのオーバーヘッド(コンテキスト切り替えやタスク間通信要求へのサービスの所要時間)のようなある腫のパラメータは対象となるシステムで実測可能。
l タスクの実行時間などは推定するしかない。
l 効率にかかわるパラメータの推定精度にシミュレーションの精度が依存する。
11.3 Petriネット
有限状態機械(finite state machine、起こったイベントの種類だけでなくそれ以前に何が起こったかに依存する有限個の状態に依存して動作する)がイベント列のモデルに利用されてきたが逐次的な制約が強すぎるので並列性を表現できない。⇒別のモデル化手法: Petriネット(Petri net)は直接的に並列性を表現し、有限状態機械を逐次的なサブ・セットとして含む。
図 1
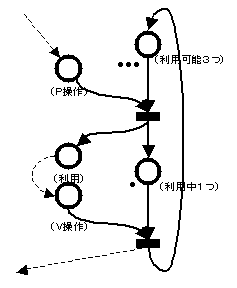
: セマフォを示すPetriネットの一部
l Petriネットはプレース(place、円で表される)ととトランジション(transition、線で表される)と呼ばれる2種類のノードを持つ有向グラフとして表される。
l プレースにはトークン(token)と呼ばれる目印が付けられている。
l トランジションに入力のある全てのプレースにトークンが揃うとトランジションは発火(fire)する。
l トランジションが発火するとトランジションの入力側の各プレースからトークンが一つずつ取り除かれて出力側のプレースに移される。
拡張
様々にあるが、特に時間Petriネット(timed Petri net)は実時間システムのモデル化に有用。これはトランジションの発火の際に0でない有限の時間が経過する。これを用いれば効率の観点から解析できる。
応用
ハードウェア・システム、通信プロトコル、ソフトウェア・システムについてモデリングツールとしてだけでなく解析ツールとしても役立つ。
モデル化の事例: タスクの同期、タスク間のメッセージ通信、Adaの並行タスク・アプリケーション
解析の事例: 可達性(reachability)とデッド・ロック(dead lock)の検出、統計的Petriネットによるスループットの解析。
以上から応答時間とスループットが重要となる実時間・分散システムではPetriネットは魅力的。
11.4 実時間スケジューリング理論
11.4.1 導入
l ハードな時間制約を持った並行タスクの優先度に基づくスケジューリングに関する理論。
l タスク群について個々のCPU利用率(CPU utilization)がわかっている際に時間制約を満たすかどうかをどのように決定するかについての理論。
l 優先度に基づく先取りスケジューリングを仮定(3章)。
l この節の内容はSoftware Engineering Instituteの実時間スケジューリングに関するレポート[Sha90, SEI93]に基づいているので、より詳しくはそちらを参照。
l 実時間スケジューリング理論は段階的に複雑なものを含むように進化してきた。
l 独立した定期タスク→定期タスクと不定期(非同期)タスクの混在、タスク間の同期が必要な場合→Adaにおける並行タスクのスケジューリングというように段階的に複雑な内容を含む。
11.4.2 定期的なタスクのスケジューリング
対象
独立した(通信・同期なし)定期的なタスク群
定義
周期Tで一回あたりの実行CPU時間がCであるようなタスクのCPU利用率U=C/T (1周期に対する稼働時間の比)
スケジュール可能性
タスクがスケジュール可能 ⇒ タスクが時間制約を満たすこと (=1周期が終わる前に1周期分のタスクが完了すること)
タスク群がスケジュール可能 ⇒ 各タスクが時間制約を満たすこと。
rate monotonic algorithm(monotonic・・・単調、「比例単調アルゴリズム」?)によれば、タスクは周期に基づく固定した優先度(短周期のもの程優先度高)を持つ。
例: 周期がta=10, tb=20, tc=30であるタスクの優先度はタスクa, b, cの順。
11.4.3 利用率束縛定理
n個の独立したタスクがいつも時間制約を満たすためには利用率の合計に制限があります。
定理1 利用率束縛定理(UTILIZATION BOUND THEOREM)
rate monotonic algorithmでスケジュールされたn個の独立タスクが時間制約をいつも満たすためには
C1/T1 + …+Cn/Tn ≦ n(21/n – 1) = U(n)
であればよい。ここでタスクtiの実行時間はCiと周期はTi。
l U(n)はln 2、約69%に収束する。
l 9つまでの計算例を本文の表11.1に示す。
l これはランダムにタスクを選んだ最悪の場合で、[Lehoczky89]では上限が88%にもなる例が示されている。
l 周期が調和している(タスクの周期が倍数の関係になっている)場合、いっそう上限は高くなる。
l rate monotonic algorithmでスケジュールされている場合、過負荷に陥った場合の挙動が安定している。即ち高い優先度を持つ(周期が短い)タスクだけを含む部分集合は時間制約を満たす。プロセッサの負荷が上がると低い優先度を持つものから時間制約を満たせなくなる可能性が出てくる。
例: 以下のような3つのタスクについて利用率束縛定理を適用する。単位はmsec.でUi = Ci/Tiである。
t1: C1 = 20; T1 = 100; U1 = 0.2
t2: C2 = 30; T2 = 150; U2 = 0.2
t3: C3 = 60; T3 = 200; U3 = 0.3
タスクの開始、終了時のコンテキスト切り替え時間はCPUタイムに含まれると仮定。
l 使用率の合計は0.7で定理1による上限は0.799なので上のタスク群はいつでも時間制約を守れる。
一方、
t3: C3 = 90; T3 = 200; U3 = 0.45
であったとする場合:
l 使用率の合計は0.85となり定理1の合計を超えるのでタスク群は時間制約を守れなくなる可能性がある。
l しかしこの場合でもタスクt1、t2について利用率の合計0.4はタスクが2個の場合の上限0.828を下回っているので、rate monotonic algorithmの安定性からこの2つのタスクは必ず時間制約を守れる。
l この定理1は悲観的な定理であり、タスクt3が実際に時間制約を守れるかどうかはより正確な定理2で確かめることができる。
11.4.4 完了時間定理
利用率の合計が定理1の上限を超えたならば、スケジュール可能性について、より正確な規準を与える定理2によって検査できる。
対象
定理1同様、独立な定期タスクについて考える。
最悪のケース([Liu73, Lehoczsky89])として全タスクが同時に実行開始を要求した場合を考える。
スケジュール可能性
各タスクが最初の周期を終わる前に完了できれば、時間制約は満たされる。(定理2では各タスクtiについて順に最初の周期内に実行を終了できるかを見る。)
定理2 完了時間定理(COMPLETION TIME THEOREM)
1群の独立タスクについて、同時に開始された各タスクが最初の周期で時間制約を守れるならば、それらをどのような時間にスタートするように組み合わせても時間制約は守られる。
l このチェックを行うには、与えられたタスクtiの周期の終わりについて調べるのと同時に、全てのより高い優先度の(=より短い周期でtiから制御を奪って1回以上実行されている)タスクについても、関係のある全ての周期について調べる必要がある。
例:(前節の後半と同じ)
t1: C1 = 20; T1 = 100; U1 = 0.2
t2: C2 = 30; T2 = 150; U2 = 0.2
t3: C3 = 90; T3 = 200; U3 = 0.45
本文のタイミング図11.1参照。
1. 同時に3つのタスクが開始。(0msec)
2. 優先度の高いt1が1回目の実行開始-完了。(0-20msec)
3. 次いでt2が1回目の実行開始-完了。(20-50msec))
4. t3が1回目の実行開始(50msec実行)・・・。(50-100msec)
5. 優先度の高いt1の周期が回ってきてt3に割り込んで2回目の実行開始-完了。(100-120msec)
6. t3が1回目の実行続行(30msec実行)・・・。(120-150msec)
7. t2の周期が回ってきてt3に割り込んで2回目の実行開始-完了。(150-180msec)
8. t3が1回目の実行続行(10msec実行)-完了(次の周期まで残り10msec)。(180-190msec)
l 以上から3つのタスクは時間制約を満たす。
l 200msecの時点でCPUの残り時間は10msecであり、CPUの利用率は合計95%。
l 利用率の単純合計は85%
l 3タスクの周期の公倍数にあたる時間(例えば600msec)での利用率は85%(平均)となる。
11.4.5 完了時間定理の数学的定式化
完了時間定理は以下の定理3のように数学的に表現できる。
定理3
rate monotonic algorithmでスケジュール
された1群の定期タスクが時間制約を守れるのは
以下の式が成り立つときで、かつそのときに限る。
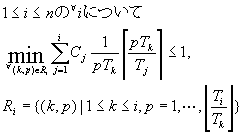
ここで、Cj、Tjはそれぞれタスクtjの実行時間と周期である。
解説
l
![]() はx以下で最大の整数。
はx以下で最大の整数。![]() はx以上で最小の整数。
はx以上で最小の整数。
l Riは、優先度iまでの優先度を表す各kと、優先度iであるタスクの1周期の間に優先度kであるタスクが繰り返される回数pの対からなる集合。
∃i、∃(p,k)∈Riに関して:
l pTkは、優先度iのタスク1周期の間に開始された優先度kのタスクの各周期の合計時間。
l
![]() は優先度iのタスク1周期の間に開始された優先度kのタスクの全周期の合計時間に優先度jのタスクが実行開始される回数。
は優先度iのタスク1周期の間に開始された優先度kのタスクの全周期の合計時間に優先度jのタスクが実行開始される回数。
l Σの一項分は、優先度iのタスク1周期の間に開始された優先度kのタスクの全周期の合計時間における優先度jのタスクのCPU利用率。
l Σであらわされる総和は、優先度iのタスク1周期の間に開始された優先度kのタスクの全周期の合計時間における、優先度iのタスク以上の優先度を持つ全タスクの利用率合計。
以上から条件全体について:
l 全タスクが時間制約を満たす。⇔∀iに関して利用率合計の(i以下の全てのkに関する)最小値が1より小さいこと
適用例
例:(前節と同じ)
t1: C1 = 20; T1 = 100; U1 = 0.2
t2: C2 = 30; T2 = 150; U2 = 0.2
t3: C3 = 90; T3 = 200; U3 = 0.45
i=1: R1={(1,1)}
(1,1): C1/T1 = 0.2 ≦1
i=2: R2={(1,1),(2,1)}
(1,1): C1/T1+C2/T1 = 0.5
(2,1): C1/T2+C2/T2 = 0.33… ≦1
i=3: R3={(1,2),(2,1),(3,1)}
(1,2): C1/T1+C2/T1+C3/T1 = 1.4
(2,1): 2C1/T2+C2/T2+C3/T2 = 1.066…
(3,1): 2C1/T3+2C2/T3+C3/T3 = 0.95 ≦1
以上よりt1、t2、t3はスケジュール可能。
11.4.6 定期的なタスクと不定期なタスクのスケジューリング
rate monotonic algorithmの拡張
l 非定期タスクの処理はある周期Taを持つ論理的な周期タスク内で一度に行われると仮定する。
l このタスクの周期Taはこのタスクを起こすイベントの間隔の中で最小の値とする。
l このタスクのCPU時間Caは以下のように決まる:周期毎に値Caのチケットが予約される。
1. 周期内でイベントが到着し場合、周期タスク内でチケットが消費され単位時間CaのCPU時間が消費される。
2. 周期内にイベントが到着しなかった場合、周期タスク内でチケットは単に破棄される。
l 以上の仮定に基づいてこのタスクの利用率をCa/Taと決定する。しかしチケットは毎回要求されるわけではないのでこの評価は最悪時の評価となる。
sporadic server algorithm
(sporadic・・・散発的、「散発的サーバアルゴリズム」?)
多くの非定期タスクがある場合に利用できる。スケジュール可能性を解析する立場からは、以下のように考えられる。
l 非定期タスクは、このタスクを起こすイベントの間隔の中で最小の値が周期であるような定期タスクと同一視される。
l このタスクの周期Taはこのタスクを起こすイベントの間隔の中で最小の値とする。
l 各タスクは単位CPU時間としてCaを「蓄え」として割り当てられる。
l 割り当てられたCaは周期Ta内の任意の時点で消費される。
l この方法において非定期タスクは、その周期に従って異なった優先度に置くことができ、定期タスクと同様に扱うことができる。
11.4.7 同期のあるタスクのスケジューリング
実時間スケジューリング理論はタスク間の同期を含むように拡張できる。
優先度逆転(priority inversion)問題: クリティカル・セクションに入ったタスクが、そのクリティカル・セクションに入ろうとする高位の優先度を持つタスクをブロックし得る。
無制限の優先度逆転: 高レベルのタスクをブロックした低レベルのタスクが、別の高レベルなタスクにブロックされ得る。クリティカル・セクションが大変短ければ、クリティカル・セクション内での先取りスケジューリングを止めることで回避可能。
priority ceiling protocol
(ceil・・・天井を張る、「上限付き優先度プロトコル」?)
自分より高位のタスクを高々1つしかロックできないようにすることによって相互デッド・ロックを回避し、優先度逆転に制限を設ける。以下、簡単のためクリティカル・セクションが1つの場合を考える。
l 調整可能な優先度: 自分より高優先度のタスクをブロックしたタスクの優先度をブロックした一連のタスクのすぐ上まで上げる。目的はブロックしたタスクの実行を早く終えて、ブロックする時間を縮めること。これによって長時間高優先度タスクを止めないようにできる。
l priority ceiling P操作付き二値セマフォS: セマフォSはこのセマフォを獲得しようとする全タスク中で最高の優先度を持つ。従ってこのセマフォを得ようとする低優先度タスクはブロックしようとするタスクの優先度に応じて優先度が上げられる。
l 相互デッド・ロック: 2つのタスクが、実行を完了するために互いのリソースを必要としている場合。priority ceiling protocolはこれを取り扱うことができる。
11.4.8 一般化実時間スケジューリング理論
実時間問題では、rate monotonicという前提が成り立たない。⇒基本的なrate monotonic スケジューリング理論の拡張の必要
例1:前節の優先度逆転問題
例2:非同期タスクを同期タスクとみなす手法をとる場合に、非同期タスクについて見かけ上の周期の短さ(=優先度)が同期タスク以下になるが、非同期タスクはイベント駆動であるのでイベント発生後すぐ実行される必要がある。
用語
本文中で「優先度(priority)」や「優先度逆転(priority inversion)」が使われているがその意味は以下の通り:
rate monotonic優先度(rate monotonic priority)
周期に基づく優先度であって、重要度に基づく優先度ではない。タスクの実際の優先度はこの通りではないかも知れない。
rate monotonic 優先度逆転(rate monotonic priority inversion)
実際の優先度と一致しない場合に、rate monotonic優先度について優先度逆転が起こっている場合をさす。
rate monotonic優先度逆転の例
2つのタスクを考える:
25msecの定期タスク
最短50msec間隔で呼ばれる非定期タスク
rate monotonic優先度は定期タスクの方が高いが実際の優先度はイベント駆動を実現するために非定期タスクのほうが高い。⇒非定期タスクが先取るたびに、逆転が発生。
拡張
目標:
l 低優先度タスクによるブロッキングを取り扱う。
l rate monotonic優先度に従わない高優先度タスクを取り扱う。
rate monotonicスケジューリングに従う場合、後者は前者に似ている。
ti :周期Tiの間に単位CPU時間Ciを消費。
というタスクについて考える。
以下の条件を考えて、どの時間制約へ最初に行き当たるかを考える。
a) より短い周期のタスクに先取りされる時間:
何度もにわたってタスクtiを先取りするj個のタスクの群Hnについて、Hn内のタスクtj(周期Tj、CPU時間Cj)についてTj<Tiならば、タスクtjの利用率はCj/Tj
b) tiの実行時間:
タスクtiがTiの間に一度だけ実行され、単位時間CiのCPU時間を消費する。
c) より長い周期の高優先度タスクに先取りされる時間:
H1に属するrate monotonicに従わない優先度を持つk個のタスクについて、これらのタスクが消費するCPU時間をCkとすると、最悪の場合のタスクtkによる利用率はCk/Ti
d) 低優先度タスクにブロックされる時間:
ブロックするタスクは長い周期を持つので回数は1。遅れは個々のタスクがブロックする状況(priority ceiling protocolによって与えられる)に基づいて解析する。与えられたタスクtiについて最悪のブロック時間がBiならば、ブロック時間について利用率はBi/Ti。
以上から・・・
定理4 一般化利用率制限定理
(条件は上述)
![]()
説明
l 最初の項の和はa)後ろの項の()内最初の項はb)、次はc)、最後の項の和はd)の条件に対応。
l こうして求めたUiが最悪時(本文の表11.1)の上限を下回っていれば時間制約は満たされる。
l rate monotonicアルゴリズムのような安定性が保証されないために、各タスクについてUiを計算する必要があることに注意。
l この判定が失敗した場合、「一般化完了時間定理」によってより正確な判定が可能。上記のような条件を考慮した上で、完了時間を検討する。この定理は図的にはタイミング図によって説明できる。
11.4.9 実時間スケジューリングと設計
設計段階あるいはインプリメント後において、実時間スケジューリング理論が一群の並行タスクに対して適用できる。(本書では設計段階での適用に重点を置く。)
l 設計段階ではあらゆるCPU時間が推定値であることによく注意する。
l 実時間システムは厳しい時間制約があるので、より悲観的なCPU利用率制限定理(最悪の上限0.69)を信頼するようにするのが安全(実時間スケジューリング理論による上限値はしばしばこれより上になるけれども)。
l 上限値を満たせない場合は別の方法を探す必要がある。
l 悲観的な設計者の観点からは、0.69を超える利用率上限はあまり深刻な時間制約がないシステム(守れなくてもあまり深刻なことにならない)でしか受け入れられない。
設計時における優先度決定問題:
l 一般にrate monotonicな優先度付けが用いられる。
l rate monotonicな優先度付けは定期タスクには簡単に適応できる。
l 非定期タスクの頻度を推定し、定期タスクとみなした場合の見かけ上の周期を求めて優先度をつけることになるが、イベント駆動という側面を考えると最高の優先度が望ましい。
l 複数のタスクが同一優先度や同一周期になった場合は設計者が決定を下して解決する必要がある。一般にはアプリケーションにとってより重要なタスクの優先度を上げる。
11.4.10 一般化実時間スケジューリング定理の適用例
タスク
|
周期タスク |
t1: |
C1=20; |
T1=100; |
U1=0.2 |
|
非定期タスク |
t2: |
C2=15; |
T2=150;(最悪時) |
U2=0.1 |
|
割り込み駆動非定期タスク |
ta: |
Ca=4; |
Ta=200; |
Ua=0.02 |
|
定期タスク |
t3: |
C3=30; |
T3=300; |
U3=0.1 |
条件
l taは200msec以内に終わらないとデータを取りこぼす。
l t1、t2、t3はセマフォで守られた同一のデータ・ストアにアクセスする。
l コンテキスト切り替えのオーバーヘッドは各タスクCPU時間の先頭に含まれる。
優先度
厳密にrate monotonicな優先度ではt1、t2、t3 、taの順。
taに関する条件から実際の優先度は、ta、t1、t2、t3の順。
解析
l CPU利用率の単純合計は0.42で上限の0.69を下回っているが、rate monotonicな優先順位が破られているため個々のタスクについて検討する必要がある。
タスクta
l タスクtaは最高の優先度なので必要なときにいつでもCPUが利用できる上に、CPU時間は0.02なので必ず時間制約を守れる。
タスクt1
a. より周期の短いタスクに先取りされる時間: なし。
b. 自身の実行時間: 利用率はU1=0.2。
c. より長い周期の高優先度タスクに先取りされる時間: タスクtaが該当。利用率はCa/T1=0.04。
d. より低い優先度のタスクにブロックされる時間: t2、t3にブロックされる可能性がある。優先度打ち切りアルゴリズムに従えば、実際にブロックするタスクは高々1つなので、最悪の場合としてよりCPU時間が長いt3がブロックする場合を考える。B3=C3と仮定すると利用率はB3/T1=0.3。
以上から最悪の場合の利用率合計は0.54で上限の0.69を下回っており、t1は時間制約を守れる。
タスクt2
a. より周期の短いタスクに先取りされる時間: t1が該当。U1=0.2。
b. 自身の実行時間: 利用率はU2=0.1。
c. より長い周期の高優先度タスクに先取りされる時間: タスクtaが該当。利用率はCa/T2=0.03。
d. より低い優先度のタスクにブロックされる時間: t3にブロックされる可能性がある。B3=C3と仮定すると利用率はB3/T2=0.2。
以上から最悪の場合の利用率合計は0.53で上限の0.69を下回っており、t2は時間制約を守れる。
タスクt3
a. より周期の短いタスクに先取りされる時間: t1 、t2 、taが該当。U1 +U2 +Ua=0.32。
b. 自身の実行時間: 利用率はU3=0.1。
c. より長い周期の高優先度タスクに先取りされる時間: なし。
d. より低い優先度のタスクにブロックされる時間: なし。
以上から最悪の場合の利用率合計は0.42で上限の0.69を下回っており、t2は時間制約を守れる。
l 以上から4つのタスクは全て時間制約を守れる。
11.4.11 Adaにおける実時間スケジューリング
Adaの概念的なモデルは、厳しい時間制約を持つ実時間システムに対する適合性から由来している。
例:Adaのタスクは:
l 優先度によるよりもむしろ待ち行列に入れられる。
l 実行時に動的に優先度が変えられることはない。
l 優先度逆転によって高優先度タスクが低優先度タスクによって非決定的に遅延させられる。
ceiling protocolをサポートするようにAdaのランタイム・システムを変更する提案や、Adaにおける実時間システムのプログラミング・ガイド・ラインの提案から、これらの問題が検討されてきた。
11.5 イベント列解析による効率解析
要求を決定する段階で外部イベントに対する反応時間への要求が決定される。タスクを構成後、まず並行タスクへの時間割り当て量を決定する必要がある。
イベント列解析(event sequence analysis): 与えられた外部イベントを処理すべきタスクを決定する。
イベント列図(event sequence diagram): 外部イベントの到着によって発生する内部イベントの列や起動されるタスクを示す。
イベント解析の手順
外部イベント:
l ある外部イベントによって起こされるI/Oタスクを決定して、引き続く内部イベント列を決定する。(これには起動されるタスクを識別することと、それらのI/Oタスクが外部イベントに対するシステムとしての応答をすることが必要。)
l 各タスクのCPU時間を推定する。
l オーバーヘッド(コンテキスト切り替え、割り込み処理、タスク間通信、同期)のCPU時間を推定する。(その周期中に実行されている他の全てのタスクについても考慮する。)
l イベント列に関連するタスクのCPU時間の合計、実行中の他タスクのCPU時間、オーバーヘッドのCPU時間を全て加えて、イベントに指定された応答時間以下であることを確認。
l 各タスクのCPU時間に不明確なところがある場合は、最悪の推定値を利用。
全体のCPU利用率の推定手順
l 全体のCPU利用率を推定するには、与えられた時間間隔について各タスクのCPU時間を推定する必要がある。(タスクに複数の実行経路があるならば、各経路についてCPU時間を推定する必要がある。)
l 次にタスクの実行頻度を推定する。(周期タスクについては容易。非同期タスクについては平均頻度と最高頻度を考える。)
l 各タスクについてCPU時間と実行頻度を掛ける。
l 全てのタスクについて合計してCPU時間を得、利用率を計算する。
(19章にイベント列解析の適用例)
11.6 実時間スケジューリング理論とイベント列解析による効率解析
実時間スケジューリング理論とイベント列解析による効率解析の組み合わせについて。
l 個々のタスクについて考えるのではなくイベント系列に関連した全タスクについて考える必要がある。
l 外部イベントによってあるタスクが起動⇒内部イベントの列が発生⇒内部タスクが起動・実行される。
l 一連のタスクが時間制約を守って実行される必要がある。
手順
l イベント系列内の全てのタスクに同じ優先度を割り当てる。これらのタスクは実時間スケジューリングの観点からは一つの同一化タスクとみなしてよい。
l この同一化タスクのCPU時間は、これら一連のタスクのCPU時間に、コンテキスト切り替えや、タスク間のメッセージ通信、イベント同期のオーバーヘッドを加えたもの。
l このイベント系列を発生するイベントの発生し得る最短間隔でこの同一化タスクが起動され、これをこの同一化タスクの周期とみなす。
l 実時間定理を適用して時間制約を守れるかどうか確かめる。(CPU時間だけでなく高優先度タスクに先取りされる可能性、低優先度タスクにブロックされる可能性も考える。)
19章に適用事例(クルーズ・コントロール・システム)あり。
同一化タスクの問題
1つの同一化タスクにまとめることができない場合(1つのタスクが複数のイベント系列に関係する、あるいは同一化タスクの優先度のために他のタスクの時間制約達成が妨げられるなど)がある。
⇒同一化タスクを異なる優先度のタスクに分割して解析し、タスクごとに先取りや、ブロックされる可能性について検討する必要がある。その上で、イベント系列に含まれる全タスクが時間制約を守れるかどうか決定する必要がある。