6章 分散ファイル・システム
Chapter6 Distributed
File System
6.4 データとファイルの複製/6.5 要約
3.5 Data and File
Replication / 6.5 Summary
発表者:神戸隆行(kando9@is.titech.ac.jp 東京工業大学 情報理工学研究科 計算数理科学専攻)
2000/11/06(月)久野ゼミ(http://www.is.titech.ac.jp/~kando9/kuno_zemi/index.html)
データ・オブジェクトはしばしば複製される。
l
実行効率向上: 複製への並行アクセスによる透過的な並列性向上
→ 並列透過性(prallelism
transparency)
l
可用性向上: 複製による冗長性を利用した透過的な耐故障性の向上
→ 故障透過性(failure
transparency)
どちらも分散システムにとって好ましいが、これらを利用するには前提条件がある。
l
クライアントが複製の存在を意識しない(単一コピーしか認識できない&複製に対するTransactionの結果が単一のオブジェクトに対するTransactionの結果と等価)で済む。
→ 複製透過性(replication
transparency)
l
データ・オブジェクトを共有するクライアント間で干渉が発生しない。
→ 並行透過性(concurrency
transparency)
Transactionの原子性:
l
Transactionは完了するか全く行われないかのどちらか
→ 前節(原子的transaction atomic
transaction)で説明: ロックや2段階コミット・プロトコルにより実現
l
共有オブジェクトに対するTransactionは並行実行されても逐次実行された場合と等価
→ 前節(原子的transaction atomic
transaction)で説明: 並行制御に関して幾つかの方法[2段階ロック、タイム・スタンプ順、楽天的並行制御]
l
複製全てに対する更新が原子的(原子的更新 atomic update)
→ 複製のある場合に追加される制約で、この節で説明。
単一コピー逐次化可能性(One-copy serializability):
原子的transactionと原子的更新という性質をあわせた性質
原子的更新という性質は:
l 複製を管理する必要のある場合はtransactionサービスに限らず一般的
l ある種の応用では、効率や可用性がデータの整合性より重要なので、Transactionが要求するより複製データの管理への制約は弱い。
原子的更新と類似(グループの概念を利用)の問題におけるアプリケーションごとの相違点:
l
原子的マルチ・キャスト:
故障していないグループ・メンバへの信頼でき、total順序を保存するメッセージ配送(メッセージが操作を表すとすると、ある操作が他の全ての操作に干渉する特殊なTransactionと考えられる):
¨ 前提となるtransportサービスの信頼性
¨ マルチ・キャストの意味付けによってtotalからcausalやFIFOへの順序条件の緩和
l
原子的Transaction:
Transaction内の全ての操作は全て完了するか全て実行されないかのどちらか。並行に実行されるTransaction間で競合する操作群はTransactionが逐次実行された場合と同順で実行される。
l
原子的更新:
複製されてできた全てのオブジェクトからなるグループに更新が波及しする。更新は逐次化される。(全ての操作が干渉するようなTransactionに類似)
¨
クライアントが最新の更新にだけ興味があり、整合性に関心がない。
(緩和)→ 少なくとも1つが読み取れればいい。
→ 複製の管理をマルチ・キャストやTransactionの観点から取り扱える。(より実際的に複製を管理するためにこれらをどのように調整するかは後述。)
複製管理のためのアーキテクチャ(図6.9):
クライアント/サーバモデル(分散トランザクションの説明に利用したpeerアーキテクチャ(図6.6)とは異なる)を利用している。
l ファイル・サービス・エージェント(File Service Agent FSA): クライアントがデータ・オブジェクトにアクセスする際に1つ以上の複製マネージャのフロントエンドとして機能し、複製へ透過的にアクセスできるようにする。
l 複製マネージャ(Replica Manager RM): 複製を管理し実際のデータオブジェクトを読み取ったり更新したりする。
複製マネージャとファイル・サービス・エージェントを融合させれば、ピア・アプリケーション群の特別な例(同一だが複製されたオブジェクトを並行に編集する(concurrent editing))が得られる。
l 読み取り(read)
l 更新(update)
¨ 上書き(overwrite)
¨ 読み取って修正して書き込み(read-modify write)
(以下では更新と書き込み(write)を同一視する。)
クライアント側の視点:
1つ読み取れればいい。(それが最新のデータであるようにする必要があれば、1つ以上のRMにアクセスする必要が出てくる)
FSAの読み取り操作の選択肢:
l Read-one-primary: 整合性を保つために単一のプライマリRMからの読み取り。
l Read-one: 並行性を高めるためにどれか1つのRMから読み取り。
l Read-quorum: 最新のデータを決定するため選抜集団から読み取り。
システム側の視点:
書き込み操作は全ての複製に自動的に及ぶべきだが、アプリケーションによっては整合性の条件は同時よりは緩和できる(全てあるいはいくつかの複製に適宜更新が伝播しさえすればいい)。
l Write-one-primary: 単一のプライマリRMに書き込み操作を行うと、そこから他のセカンダリRMに更新が伝播される。
l Write-all: 全てのRMに対する書き込み操作は原子的に行われる。(それ以降に行われる書き込み操作は原子的な実行が完了するまで待たされる。)
l Write-all-available: 利用可能な(故障のない)全ての全てのRMに対する書き込み操作は原子的に行われる。故障から回復したRMは利用可能な状態になる前に整合の取れた状態になるように復旧する。
l Write-quorum: 選抜集団全体への書き込みは原子的に行われる。
l Write-gossip: 更新はどのRMに行っても良く、後でその他のRMへlazilyに伝播する。
複製されたオブジェクトに対するトランサクションが、複製のない単一のオブジェクトへのトランザクションと等価。
l 読み書きはプライマリRMに集約されるので複製の整合性に関する問題は存在しない。
l 並行性の恩恵はない。
l 複製は冗長性を増して可用性を高めるためだけに利用される。
l Read-one-primary/Write-one-primaryに比べて並行性は高まる。
l 整合性の問題がある。(書き込みが行われたRMから他のRMへ書き込みが伝播する際の遅れのため)
l 原子的な更新を可能にするプロトコル(2フェーズ・ロック、2フェーズ・タイム・スタンプ順序付け)が利用できれば、どのRMからでも整合性を保ったまま更新できる。
l 読み書きの操作がSubtransactionであれば、One-copy逐次化可能。
l Write-allという仮定は複製管理に際して現実的ではない(故障を許容する目的で複製を作る場合、原子的な更新はその目的と矛盾)。
l Read-one/Write-allに比べて故障を許容する。
l One-copy逐次化可能性の達成は若干難しくなる。
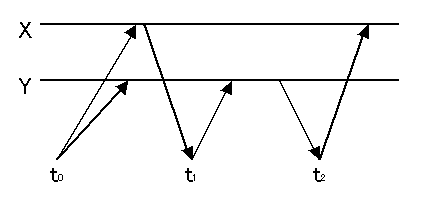
例)
t0 : bt W(X) W(Y) et
t1 : bt R(X) W(Y) et
t2 : bt R(Y) W(X) et
(btはbegin transaction, etはend transaction)
t1 : bt R(Xa) (Ydが故障) W(Yc) et
t2 : bt R(Yd) (Xaが故障) W(Xb) et
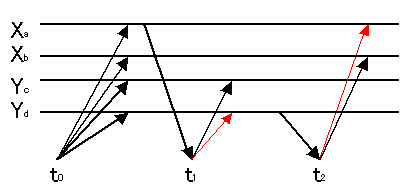
こうなるとt1とt2の間に(本来ある筈の)Conflictが発生せず、複製がない場合と結果が異なる。
l 故障と回復もトランザクション毎に逐次化されていなければならない。
¨ t2のトランザクションの完了前にYdが故障したらt2でのYdの読み出しも不正。
¨ t1での書き込みの際にYdが故障したら、t2ではYdからの読み出しを中断してやり直し(結果としてYdではなくYcを読む)せねばならない。(=故障はトランザクションの開始前に現れねばならない。)
l 故障を許容するには制約を追加する必要がある。→12章の複製管理に関する節: serialization graphの非循環
l 動機: 前節の例でt2がYの複製のグループYcとYdを読むようにすればConflictが表面化させられる
l →詳細は次節
l オブジェクトdに対する:
¨ R(d): 読み取り選抜グループのメンバ数
¨ W(d): 書き込み選抜グループのメンバ数
¨ V(d): オブジェクトdに関する総投票数(=複製の数)
¨ コンフリクトを解決するための選抜集団の大きさに関する条件:(グループの大きさが過半数を超えれば重なりが発生する。)
l 書き-書きコンフリクト: 2 * R(d) > V(d)
l 読み-書きコンフリクト: R(d) + W(d) > V(d)
l semi-unanimous(半合意)選抜投票(semi-unanimous quorum voting)の特別な場合
l One-copy逐次化可能とするためには2フェーズ・ロックorタイム・スタンプ順序を利用すればよい。
l
最新データ読み込みの保証:
オブジェクトにバージョン番号を振って読み取り選抜の中で最新のものから読み込む。
書き込む際は書き込み選抜内で「最新の版番号+1」へと版番号を更新
→図6.10・・・R(d)=5、 W(d)=5、 V(d)=9、書き込み選抜内の複製のバージョンは8、読み込み選抜内では6〜8があるので8が最新。
l
分割のバリエーション:
多くのアプリケーションではW(d)
> R(d)
¨ R(d)=1, W(d)=V(d)は Read-one/Write-allを表現
¨
W(d) < V(d)ならばWrite-all-availableのように故障を扱える(ただしR(d) > 1)
Read-quorum/Write-quorumはRead-one/Write-allとRead-one/Write-all-availableの良い折衷案になっている。
l
立会人(witness or ghost):
R(d)よりW(d)がかなり多い場合、書き込み選抜を拡張して、書き込み選抜に参加する「立会人」(オブジェクトの複製を保持せず、投票用のバージョン番号とオブジェクトの識別情報だけを保持する)を利用して書き込みのオーバーヘッドを減らすことができる。(・・・複数の書き込み選抜間で最新の版番号を共有する際に役立つ)
→図6.10・・・書き込み選抜内に2つ「立会人」が混じっている。
l
投票にRM毎の重み(可用性や効率の差異を表現)をつけることもできる。
l 幾つかのアプリケーションでは強い整合性:
¨ Read-one/Write-all-availableでのOne-copy逐次化可能性
¨ Read-quorum/Write-quorumでの最新の更新を知ること
・・・は不要。
l 読み取りに比べて更新が頻繁でなく、更新順序に関する条件が緩くてよいならば、RM間で更新をlaizilyに伝播(実生活における噂話(ゴシップ Gossip)のように)させることができる。
l このRead-one/Write-gossip方式は別名gossip update propagation protocol
l 第一の目的は:
¨ 複製の故障がおきやすい
¨ 信頼性のあるマルチ・キャストが実際的でない
・・・という環境での可用性の向上。
図6.11はゴシップ更新伝播プロトコルの簡単な実装:
1.
上書き更新(overwrite
update)を仮定する実装
・・・グループが固定でなければ更新ログは不要。
2.
読み取り-修正更新(read-modify
update 更新時の状態に依存)を仮定する実装
・・・データの依存性解析のために更新ログを利用。
を説明するためのアーキテクチャ
TSi : 各RMiの保持するタイム・スタンプで、最新の更新時刻を表す。
TSf : 各FSAの保持するタイム・スタンプで、最新のアクセス成功時刻を表す。
(プロトコルはread, update, gossipメッセージに対するFSA、RMiの反応として記述)
Read :
1.
TSf ≦ TSiの場合: FSAはRMiの情報を最新のものとして受け取り、TSf
:= TSiとする。
TSf > TSiの場合 : FSAはRMiがGossipで更新されるのを待つ。FSAは他のRMにアクセスを試みても良い。
Update :
1. TSfを1増加させる。
2.
TSf > TSiの場合:更新が実行され、TSi :=
TSfとする。RMiは適宜Gossipによってこの更新を他のRMへ伝達してもよい。
TSf ≦ TSiの場合:
並行的な更新があったか、更新が遅すぎたかのどちらかを示し、対処はアプリケーション(上書き更新・・・無視or読み取り-修正更新・・・やり直し)により異なるが、どの場合でもTSf := TSiとする。
Gossip :
1. RMjからRMiへのGossipはTSj>TSiの場合に受け付けられ、TSi := TSjとしてメッセージの運んできた値へ更新が行われる。RMiはGossipによってこの更新を他のRMへ伝達してもよい。
グループが固定であればベクトル型タイム・スタンプが利用できる。
利点: 各RMiで何回更新が行われたかを示す版番号が作れる。
例:
TSi = <2, 3, 4>はそれぞれRM1, RM2, RM3での2,3,4回の更新を示す。
TSf=<2, 2, 2>であれば、どれからでも読み取れる。
TSf=<2,5,5>であれば、待つ必要があるが、最新のデータがRM2, RM3にあることもわかる。
読み取り修正更新は読み取りと上書きの対よりもメッセージが少数ですんで効率が良い。
ベクトル型タイム・スタンプと順序に従って更新を保存するバッファ(=ログ)でcausal順序を保存する読み取り-修正更新が実装できる。
(参照: ベクトル型タイム・スタンプを利用したcausal順序を満たすマルチ・キャスト・・・4.1.5節)
V :当該RMが擁するオブジェクトの現在の更新状況を表すベクトル型タイム・スタンプ
R :グループ内の他RMでの更新状況に関して当該RMの持つ知識(Gossipを通じて伝播、要素ごとの最大値を取って2つのRを併合)を表すベクトル型タイム・スタンプ
L : 更新ログ。各更新u(FSAが更新を発行した際のタイム・スタンプで表される)について固有な識別子rとその操作のタイプと値からなるレコードのリスト。
Read
1. FSAは問い合わせqにベクトル型タイム・スタンプTSfを割り当てる。
2.
q ≦ V : RMはFSAにオブジェクトの値を返す。qにVを併合することによってFSAのタイム・スタンプは進められる。
q > V : 更新されるのを待つか他のRMに問い合わせる。
Update
1. FSAは更新uにベクトル型タイム・スタンプTSfを割り当てる。
2.
u < V (通常は発生しない・・・このような要求を出したFSAは現状を把握できていない。このような更新に先立って読み取りが行われるべき。)の場合:
更新は遅れすぎなので拒絶される(causal順序を守るため)。
u ≧ V (Causal順序のついた更新)の場合
あるいは
u < V でも u > Vでもない(並行的な更新)の場合:
RMiにより更新は受け付けられる。Ri(RMiのベクトル型タイム・スタンプ)のi番目を1増加。ユニークな識別子rと共に更新操作uをLi(RMiのログ)に記録。
特にu = V(u ≧ Vの内で)の場合:
更新は実行される。rがV(RMiのベクトル型タイム・スタンプ)に併合される。
l ・・・この結果としてログ中の幾つかの操作(uとする)が確定(stable)の条件(u ≦ V)を満たす。(→ログ中でこの条件を満たす操作は実行されてしまっていてよい=実行準備が整っている)
l 確定した操作はベクトル型タイム・スタンプを参照してCausal順序に従って実行される。
l 確定していない操作は確定するのをログ中で待つ。(確定はu = Vを満たす更新かその更新がGossipとして伝わって起こる。)
l 実行された操作はログから(更新をGossipで伝播するため即座にではないが)取り除かれる。
Gossip
1.
RMjからRMiへのGossipメッセージはRj(RMjのベクトル型タイム・スタンプ)とLj(RMjのログ丸ごと・・・1つのみならず他のRMの情報も含む「真の」ゴシップ)を含む。
RjはRi(RMiのベクトル型タイム・スタンプ)に併合される。
LjはLi(RMiのログ)に結合される(RMiで既に数えられているはずのr ≦ Viとなるようなレコードを除く)。
例(図6.11):
l 更新とゴシップの伝播、タイム・スタンプの変化は図の通り。
l タイム・スタンプの初期値は<0,0,0>
l
RM1への更新u1<0,0,0>
・・・即実行。V1=<1,0,0>,
R1=<1,0,0>, L1 ={<r1,u1>}
→ RM2への更新u2<1,0,0>
・・・V2=<0,0,0>,
R2=<1,1,0>, L2={<r2,u2>}
, RM3への更新u3<1,0,0>
・・・V3=<0,0,0>,
R3=<1,0,1>, L3={<r3,u3>}
→ RM2へu1のGossip
・・・V2=<0,0,0>, R2=<1,1,0>,
L2={<r2,u2>,<r1,u1>}
→ RM3へu1,u2のGossip
・・・V3=<0,0,0>,
R3=<1,1,1>, L3={<r3,u3>,<r2,u2>,<r1,u1>}
l
L2のr1は確定→r1が実行されてV=<1,1,0>となってr2が確定→r2が実行される。
L3のr1,r2,r3についても同様。
以上がゴシップ更新伝播の基本概念。
ガベージ・コレクションのログやメッセージ数の最適化は12章を参照
l 本章のテーマは分散ファイルシステムの概念と設計。
l 分散ファイルシステムはどのような
¨ ファイル共有の意味付け(file sharing semantics)
の元でファイルの
¨ 分散(dipersion)
¨ 多重化(multiplicity)
¨ 効率(performance) → キャッシュ(caching)
¨ 可用性(availability) → 複製(replication)
¨ スケーラビリティ
¨ 故障許容性(fault tolerant)
をどのように透過的(transparent)に実現したかで特徴付けられる。
l ファイルアクセスと位置透過性 ← 階層的な名前付け構造、ファイル・マウント・プロトコル
l ファイルサーバーの集合による分散ファイルサービスの構成・・・Statelessなサーバ(頑健で実装が簡単)とStatefulなサーバ(Stateの管理は多くのアプリケーションに望まれている)
l 同一ファイルに対する多重アクセスの結果としてのファイル共有。
¨ オーバーラップ(overlapping 空間的多重化)
Ø 効率 ← クライアント・キャッシュ
Ø 可用性 ← 複製
(↑複製間でデータの整合性を維持
→ 複製透過性)
¨ インターリーブ(interleaving 時間的多重化)
Ø セッション
Ø トランザクション
(複数のアクセス系列間の干渉を回避
→ 並行透過性)
l ファイル共有意味付けモデル(common file sharing semantics model)
¨
Unix
キャッシュ・コヒーレンス・プロトコルの選択(write-through, write-back, write-invalidated, write-update)
¨
セッション(session)
仮定: ファイル共有が頻繁には発生しない。
→ ユーザー任せ
¨
トランザクション(transaction)
データベース等のアプリケーションでは共有が本質的で頻繁に発生
Ø ACIDセマンティックス ← 並行性制御プロトコル(2フェーズ・ロック・・・操作を制限して逐次性実現、タイム・スタンプ順序付け・・・衝突が発生したときのみタイム・スタンプで解決、楽天的並行制御・・・実行フェーズでは整合性無視、検証フェーズで正当な場合のみ本実行)
l ファイルの複製
Ø 並行性向上
Ø 故障許容性向上
¨
多くのアプリケーションでは整合性(更新の順序等)への要求がゆるい
→ 複製管理プロトコル(primary copy, quorum voting, gossip update protocol)
グループ概念の利用 → 12章
([ ]内の略号は535ページのBibliography参照)
l 分散ファイルシステムの良いサーベイ・・・[LS90]
l よく引用される分散ファイルシステム・・・NFS (Sun) [SGK+85], Andrew (CMU) [MSC+86], Locus (UCLA) [PW85, SP86], Sprite (UCBerkley) [Hil86, OCD+88]
l Locus and Coda[SKK+90]はAndrewの拡張でアトミックな複製管理、ネットワークの故障と分割、並行トランザクションサービスを含む多くの特徴を備える。
l トランザクション・サービスは現代的な分散ファイル・システムの重要な一部である高レベルのサービス。その並行制御はデータベースとOSの関連で研究されている。
¨ 最初のサーベイ[BG81][BHG87]
¨ これらのテーマを含む書籍[Bha87, OV91, CDK94, Gos91, Bac93]
¨ グループの概念を利用した複数レベルのトランザクション間の協調という進んだアプリケーションに関するサーベイ[BK91]
l 複製管理には様々な観点からのアプローチ(データベース、グループ管理、更新伝播)
¨ primary copy・・・[AD76, Sto79]
¨ 選抜投票(quorum voting)・・・[Mae85, GMB85]
¨ 更新伝播(update propagation)・・・[FM82, WB84, LLSG92]
¨ データと通信の管理に関するさらに進んだトピックは12章