以上の技法はいずれもsingle threadedの場合はO(1)でのアクセスを達成している。典型的な利用例や最悪の場合の効率を上げることが課題。
ここで紹介する技法について
配列を利用するアルゴリズムの多くは配列要素を平等にアクセスし、k 回以上の参照や更新を受ける要素はない。(ここでk は定数。)従って各要素についてk回の更新までについてO(1)ならばよい。
このようでないアルゴリズムについては、平均O(log n)の時間でアクセスでき、更新1回につき空間O(1)が必要。
Chuang(1992)よりアクセスが早く、二分木に基づく方法より早く、更新時の空間消費も少ない。Dietz(1989)よりも実際的な局面では早く、平均は漸近する。
The fat element method
上記の方法(version tree arrays)では要素の変更を配列全体に対する変更の1種と捕らえていた。
一方、以下で紹介する方法では要素の変更は各要素の単位で処理される。
Fat elemrnt methodでは配列は以下の要素からなる。
Version stamp: 配列の更新歴を示す版番号
Fat element: 各要素の幾つかの版をまとめて格納したデータ構造
これらは以下の機能を持つ:
l
更新のたびに重複しないVersion stampを発行する機構
l
各要素から版に応じて適切な値をとりだす機構
Version stamps
更新によってできた新たな配列の版を表す。
l
配列がpartial persistenceなら簡単な整数カウンタとして実現できる。
l
fully persistentの場合、版が分岐するので、部分順序をサポートするversion
stampが必要になるが、それをそのまま実装しようとすると最悪O(n2)の時間・空間計算量が必要。
l
版に制約を付けて全順序化することを考える。
制約(list order problem):
現在の版の集合をVとして、版xvの配列xを更新して版yvの配列yになったとするとき、xv < yvかつ、∀v >xv(v∈V)についてv≧yv。(⇔yvはxvより大きい最小の版)
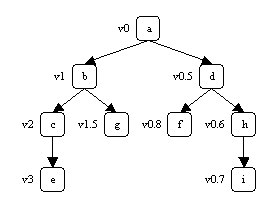
図 2: version treeにおける全順序
実装法:
l
リンク・リスト
l
版に対する実数ラベル付け (リンク・リストよりは効率がよいが、定数時間では実行できない無限精度実数演算が必要。桁数制限のある整数を利用した、実際上は定数時間で実行(挿入、削除、・・・)可能なアルゴリズムとしてDietz and Sleator(1987); Tasakalidis(1984)がある。<省略したが、この論文の付録にも解説あり。>)。
版の隣接(adjacent version):
2つの版の間に版がないこと。partial persistent(あるいはsingle threaded)な更新の場合は、更新後も版の隣接状態に変化はない。fully persistentの場合は新しい版がすでにある隣接した版の間にできることがある。
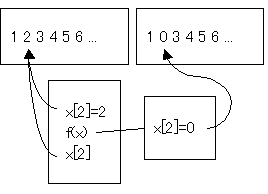
Fat element data structure
配列の版からその版が持つ値への写像を提供する。
l
論理的にfat elementの各要素は、その要素における版と値の対を複数保持するテーブル。
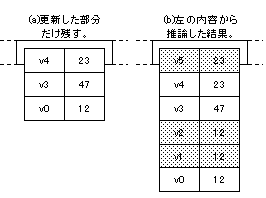
図 3: fat element における省略
l
配列の値の多くは殆どの版で同一であることに注目。⇒各要素における版と値の対は、全ての版について必要なわけではない。(ただしfully persistentな更新で省略したエントリの間に更新が入るときは要注意。)
l
版に全順序の制約をつけたので、fat elementを実装する際に効率のよい構造が利用できる。
例:バランスした2分木、更にsplay tree(Sleator and
Tarjan 1985)。最新のものは木の根にあるのでO(1)でアクセス可。splay tree ではさらにその性質からsingle threadでなくてもO(log e) (ここでeはfat element内の要素数で、e∈O(n)へ改良できる。)
改良
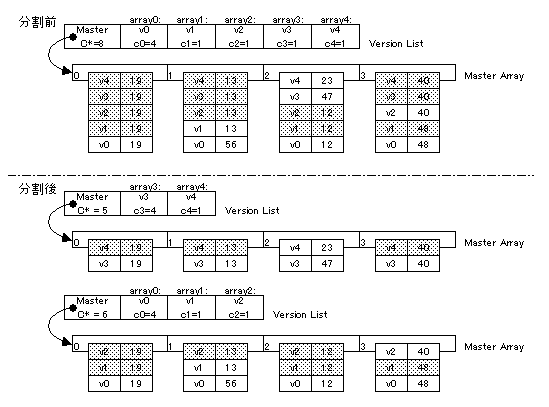
fat element内の要素数が最悪時のアクセス時間を決めているので、配列を分割してこれを減らすことを考える。
分割を開始する規準c*:
c*≦(kl+1)n
c*: Master Array内に格納されている値の数
kl:
1要素あたりの変更回数の上限を表す定数。実験で決定。
n:
配列としての要素数
分割の境界を決める規準m:
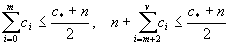
m: 分割後の配列における版数の上限。
ci: i番目の版に格納されている値の数
v: 分割前の配列における版数の上限
結果として(2+kl)n/2が分割後の配列の要素が持つ値の数の上限となるようにmを決めればよい。
補題2.1 c*=(1+kl)nであるときO(n)で分割作業が行える。(証明は省略)
平均時間解析
potential function法(Tarjan 1985)によって平均時間(amortized time)を解析する。
データ構造の各配置についてpotentialという実数値が与えられ、それを高価な操作を補償するエネルギーとみなす。よって平均時間は
(平均時間)≡(消費時間)+(potentialの増加)
として定義できる。(記号的にはTA≡TR+ΔΦ)
fat elementデータ構造のpotentialは
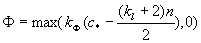
(kΦはある定数。)
なので、このΦの変化ΔΦを各操作について調べればよい。
(以下省略。)
実際の効率(実験)
利用されている他の実装(2分木とtrailer arrays)とML上で実装(ML for the working programmer(Paulson
1991)に基づく)して比較。
関数型配列についてよく知られているベンチマークはないので、
l
fully persistent
l
partially persistent
l
ephemeral
として配列を扱う簡単なテストを用意。
(結果のグラフ(Figure6 (a)-(c)、Figure7(a)-(b))は別紙。)
Figure6: Fully Persistentな例
要素数nの配列についてv個の版を作る。(ランダムに選んだ版についてランダムに選んだ要素を、同様にして選んだ2つの値の和によって更新。)、
縦軸は反復1回あたりの所要時間
(a) n=vとしてnとvを増加させる: 理論上、fat elementは最悪O(log n)だが、実験ではO(1)でカバーされる範囲に収まっていて、他の二方式より優れている。
(b) n=216としてvを増加させる: 理論上、2分木は要素数に応じて領域は増加するが、アクセス時間は一定。fat elementは定数時間アクセスだが、配列の分割が起こっているところでグラフが不連続になっている。実験結果は理論に沿っているが、不幸にしてこの要素数は少なすぎて2分木の方が高速。よって要素数が少なく版数が多いときは2分木の方が適している。
(c) v=216としてnを増加させる: 上と同様な理屈で、少数ではfat elementの定数時間のオーバーヘッドは2分木より大きいが、2分木がサイズの増加に伴って遅くなるのに対し、fat elementはサイズが増加しても定数時間(分割のオーバーヘッドが分散して一回あたりでは減少している。)。
Figure7: Partial PersistentとEphemeralな例
(a) 配列のEphemeralな逆転: 左端と右端を交換しながら内側へ処理していく。参照も更新も最新版に対して行われる。(通常の命令型逆転操作): fat elementは定数時間で、2分木よりは早いが、定数オーバーヘッド分でtrailerには負けている。
(b) 配列のPartially Persistentな逆転: 元の配列を参照しつつ左から右へ更新が進む。更新対象は最新の版だけ: trailerの弱点(O(n2))が露呈し、グラフの範囲から外れている(n=4096で4・10-2秒。Chuangの改良でO(n)までにはなるが・・・。)。 一方、fat elementと2分木についてはこのアルゴリズムのちょっとした変種を利用すれば、実質同じにできる。
fat element方式は:
l
実験結果は理論的な予測によく従っている。
l
多くの事例で実測時間が他の方法といい勝負になっていて、全ての事例について特に弱点がない。
結論
l
「理論的によい性質を持ち、極端に複雑でなく、実用上遅すぎない関数型配列のためのデータ構造。」という目標は達成された。
l
single threadedの場合に定数時間アクセス可能とはいえ、命令型配列と同じくらい早いわけではないので、完全に置き換えられるわけではない。
l
が、persistentであることが必要な場面では有効。
l
よって、他の技法(update analysisなど)の補助として有効。
例(update analysis):解析によってsingle threadedであることが判れば命令型配列を利用し、明らかにできなければfat element方式を利用する。
例(1bit参照カウント):更新について楽天的な仮定を置き、実行時に1bit参照カウントでその仮定が正しいかどうかを検出する方式とも協調できる。
l
fat elementは万能の回答ではないが、極端な弱点はないので、あまり恐ろしいペナルティを払わずに利用できるデフォルトの選択になり得る。
参考文献
(★印は神戸の手元にあるもの。)
Aasa, A, Holmström, S. and Nilsson, C., (1988), An
efficiency comparison of some representations of purely functional arrays., BIT,
28(3), pp.490-503.
Baker Jr., H. G., (1978), Shallow binding
in lisp 1.5., Comm. ACM, 21(7), pp.565-569.
Baker Jr., H. G., (1978), Shallow binding
makes functional array fast. SIGPLAN notices, 26(8), pp.145-147.
★Bloss, A., (1989), Update analysis and the efficient implementation
of functional aggregates., In: Functional Programming Languages and Computer
Architecture, London, ACM.
Chuang, T.-R., (1992), Fully persistent
arrays for efficient incremental updates and voluminous reads., In: Kürieg-Brükner, B.
editor, ESOP’92: 4th European Symposium on Programming : Lecture notes in
Computer Science 582, pp.265-274.
Chuang, T.-R., (1994), A randomized
implementation of multiple functional arrays., Conference Record of the 1994
ACM Conference on LISP and Functional Programming, pp.173-184.
★Dietz, P. F., (1989), Fully persistent arrays., In: Dehne, F.,
Stack, J. R. and Santoro, D. D., edtors, Proceedings of the Workshop on
Algorithms and Data Structures: WADS’89, pp.67-74, Lecture Notes in
Computer Science 382, Springer-Verlag.
Dietz, P. F. and Sleator, D. D., (1987), Two
algorithms for maintaining order in a list, To appear. (A preliminary
version appeared in Proceedings of 19th Annual ACM Symposium on
Theory of Computing, New York, May, 25-27 1987)
★Driscoll, J.R., Sarnak, N., Sleator, D. D., and Tarjan, R. E.,
(1989), Making data structure persistent, J. Computer & System Sci.,
38, pp.86-124.
Holmström, S., (1983), How to
handle large data structure in functional languages., Proceedings of SERC
Chalmers Workshop on Declarative Programming Languages.
Hoogerwoord, R. R., (1992), A logarithmic
implementation of flexible arrays, Proceedings of 2nd International Conference
on Mathematics of Program Construction, pp.191-207.
Hughes, J., (1985) An efficient
implementation of purely functional arrays, Technical Report, Department
of Computer Sciences, Chalmers University of Technology.
Myers, E. W., (1984), Efficient applicable
data types., In: Kennedy, K., editor, , Conference Record of the 11th Annual
ACM Symposium on Principles of Programming Languages, pp.66-75, Salt Lake
City, UT: ACM Press.
Paulson, L. C., (1991), ML for the
Working Programmer., Cambridge University Press
Schdmit, D. A., (1985) Detecting global
variables in denotional specifications., ACM Trans. On Programming Languages
and Systems, 7, pp299-310
Tarjan, R. G., (1985), Amortized
computational complexity., SIAM J., Algebraic and Discrete Methods,
6(2), pp.306-318
Tasakalidis, A. K., (1984), Maintaining
order in a generalized linked list., Acta Informatica, 21(1), pp.101-112
付録
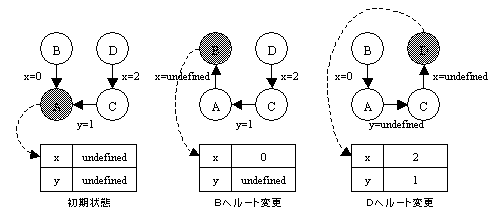
図 5
: shallow
binding法
l
ルートのノードに対応する版の配列はキャッシュされている。
l
直接キャッシュされていないノードに対応する版の配列を読むとルートが変更される。
l
各版を示すノードの数は無制限に増加し得る。([Chuang1992,1994]はツリーを途中で切り離してキャッシュを複数作る改良。)
l
複数の版をとっかえひっかえアクセスするとルート変更が頻発して効率が悪い。